GPU Acceleration of Massive Convolution - aka: How long will it take to add reverb to all
of
Avengers: Endgame?
If you're not familiar with the term reverb, it's what you hear when you clap in a
bathroom
or a church. It’s an audio effect that can make a recording sound like it’s in a church
or
in a small room. Apply it to an audio track
and now your singer sounds like they’re in a huge concert hall. There are two
mathematical
ways to apply reverb to an audio track, and the one I’m focusing on is called
convolution.
It’s got a long, technical name, but convolution reverb sounds the best. It requires an
impulse response of a room and the signal you want to add reverb to. An impulse response
is
a recording of a room. The easiest way to do it is to pop a balloon or
clap (very loudly!). The bigger the room, the longer the reverb trail will be. This
recording contains all of the sonic features of the room.
The intuitive way to apply this impulse response is to shape every single sample of your
input with the reverb. Meaning, take the first sample of your signal and multiply it by
every single sample of the reverb.
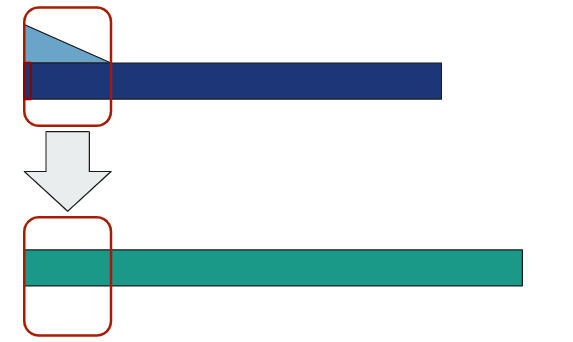
This emulates a reverb trail for the first sample. Then, continue this for every single
sample of the input. The reverb trails overlap with each other, so they are added
together.
The overlapping reverb trails is like trying to talk in a gymnasium. If too many people
talk
at once, the echoes overlap with each other and you can't hear what the other person is
saying.
Another way to think about this is that a single sample of the output is the sum of all
the
echoes in a given moment in time.
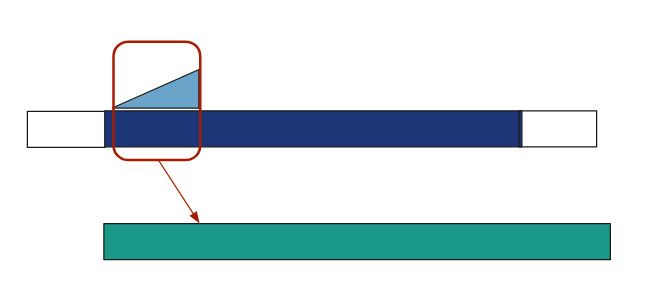
The math checks out, and both algorithms do the same thing since order doesn’t matter
with
multiplication and addition. This second way is used more often in digital signal
processing
because it has a formula:

When we tell a computer to use this formula to come up with reverb, the computer doesn’t
really like it. That’s because this method involves a huge amount of addition and
multiplication operations. The actual number of computations
is N * K, which grows to N^2 if the reverb is the same length as the input.
Ok, here’s a real-world analogy. Avenger’s: Engame is 3 hours long, or 180 minutes. At a
standard 48kHz sample rate, that’s 518.4 million samples. If we wanted to add a 10
second
reverb to the entire movie, the reverb would be
480 thousand samples. That means 518.4 million x 480 thousand = 248.8 trillion number of
operations. A standard CPU from 2014 (Intel i5-557R) can do up to 179.2 million
operations
per second. Theoretically, it would take 1,388,571
seconds = 23,142 minutes = 385 days = 1 year and 21 days to compute.
Ouch!
There is another way to do this using the Fast Fourier Transform and going into the
frequency
domain. I won’t go into details, but it’s significantly faster with a theoretical
estimate
of 263 seconds = 4.4 minutes. I call these
two methods time domain convolution and frequency domain convolution. That's a lot
better
than a year, but we can do better.
This is where the GPU comes in. A GPU also released in 2014 has a theoretical peak of
6840
million operations per second. Following the same math, it would take 10 hours using
time
domain convolution and 6.9 seconds using the frequency
domain convolution.
That sounds so much better!
The problem with these estimates is that they are impossible to reach due to physical
constraints. A computer consists of multiple parts, some of which are slower than
others.
The CPU needs to talk to the memory to get the numbers to do the computations,
and the memory is over 100x slower than the CPU.
The only way to truly find out how long it takes is through experimentation. That’s
exactly
what I did.
FFTW3 - short for Fastest Fourier Transform in the West. It is an FFT library in
C/C++ FFTW
Main Page FFTW
Documentation
CUDA - acronym for Compute Unified Device Architecture. It’s “a parallel
computing
platform and programming model developed by NVIDIA for general computing on graphical
processing units (GPUs)” (Nvidia). It is a proprietary
but free API in several different programming languages to speak directly to NVIDIA
hardware
and utilize parallel processing. General
Knowledge Download
link Documentation
cuFFT – NVIDIA CUDA Fast Fourier Transform library. General knowledge Documentation
Thrust – “Thrust is a C++ template library for CUDA based on the Standard
Template
Library (STL)” (Nvidia). It’s a library within CUDA that utilizes parallel processing
for
algorithms that already exist in C++’s standard
library such as summing, reducing, and sorting. NVIDIA
Documentation GitHub
Documentation
Libsndfile – Portable audio library used to read contents of wave files Download
link
Credits to Dr. Brian McFee for the DSP knowledge
and
Dr.
Mohamed Zahran for the GPU knowledge.
For time domain convolution, the GPU is slower than the CPU until the input size reaches
2
10. This is 1024 samples, or 10 milliseconds of audio at 96kHz.
228
samples, the highest test value for both, is just over a quarter of a billion samples,
or
about 46 minutes of audio at 96kHz. This number
of samples on a CPU took 4 days, 18 hours, and about 27 minutes to compute, while it
took 13
minutes on the GPU. That's a ~50x speedup. It's also incredibly unreasonable to wait 4
days
to process a single audio file. As started
earlier, considering that the time approximately doubles for each doubling of input
size, 2
29 is projected to take 9 days, and 230 is projected to take 19
days.
For frequency domain convolution, the GPU begins to be useful for inputs of 2
23and above. This is equivalent to 8,388,608 samples or ~87 seconds of audio
at
96kHz. At 230 samples, which is just over 1 billion samples or just over 3
hours
of audio, there is a ~44x speedup from ~8.7
minutes to ~11.8 seconds.
Combining these these results, CPU frequency domain convolution is the fastest for
inputs
smaller than 223 samples (~87 seconds), and GPU frequency domain convolution
is
the fastest for any inputs larger than that.
.jpg)
.jpg)
.jpg)
.jpg)